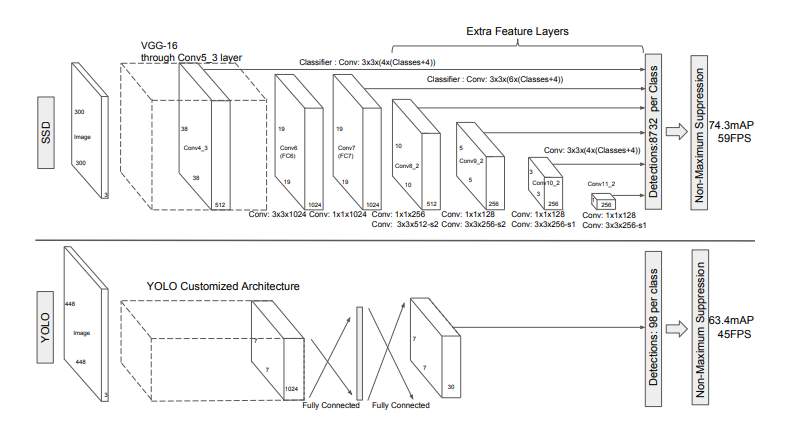
SSD란?
SSD (Single Shot MultiBox Detector)은 물체 감지(object detection)에서 널리 사용되는 딥러닝 기반 알고리즘 중 하나로, SSD는 이미지에서 물체의 위치와 클래스 레이블을 동시에 예측할 수 있는 네트워크 구조를 가지고 있다.
당시(2016년도 기준) 객체 탐지 기능의 주를 이루었던 건 Faster R-CNN과 같은 2-Stage-Detector들이었는데
이들은 성능은 좋았지만 region proposals를 추출하고 이를 처리하는 과정에서 많은 시간이 걸려 detection 속도가
느리다는 단점이 있었고, YOLO v1은 원본 이미지 전체를 통합된 네트워크로 처리하기 때문에 detection속도는 빠르나
grid cell별로 2개의 bounding box만을 선택하여 상대적으로 적은 view를 모델에 제공하기 때문에 정확도가 떨어지는 단점이 있었다. 일반적으로 정확도(mAP)와 속도(FPS)는 서로 상충하는 관계에 있는데 SSD는 다양한 view를 사용하여 정확도를 높이면서도 1-stage-detector로서 빠른 속도까지 갖춘 네트워크라 할 수 있겠다.
*region proposals: 주어진 이미지에서 객체가 있을 가능성이 높은 영역(Region of Interest, ROI)을 제안하는 기술.
주로 객체 탐지(object detection)와 관련된 작업에서 사용됨. 이미지 내에서 여러 후보 영역을 생성하고, 각 후보 영역에 대해 객체가 포함되어 있을 확률을 평가한다. 이러한 과정은 전체 이미지에서 직접 객체를 탐지하는 것보다 훨씬 효율적이며, 이후의 정밀한 분류 및 경계 박스 조정을 위해 사용됨
| 모델 | 성능(mAP) | 속도 |
| Faster R-CNN | 73.2% | 7FPS |
| YOLO v1 | 63.4% | 45FPS |
| SSD | 74.3% | 59FPS |
핵심
- SSD의 핵심은 고정된 경계 박스들을 활용, 작은 합성곱 필터를 피처 맵에 적용해서 클래스 레이블과 경계 박스 좌표를 예측한다는 것이다.
- 정확도를 높이기 위해 다양한 스케일의 피처 맵에서 가로세로 비율에 따라 분리해 여러 스케일로 예측을 한다.
- 이러한 설계 덕분에 end-to-end 방식으로 간단히 훈련이 가능하며, 게다가 입력 이미지의 해상도가 낮더라도 높은 정확도를 보인다.
* End-to-end 훈련이란 전체 시스템 또는 모델을 처음부터 끝까지 한 번에 학습시키는 접근 방식을 의미
전통적인 방법에서는 각 단계를 별도로 구현하고 학습시켜야 하지만, end-to-end 학습에서는 입력 이미지에서 출력 클래스까지의 전체 과정을 하나의 신경망이 학습한다. YOLO(You Only Look Once)와 같은 모델이 이러한 방식의 대표적인 예.
- 성능 향상: 통합된 학습 과정에서 모델이 최적화된 특징을 자동으로 학습하므로, 종종 성능이 향상.
- 간소화: 시스템 설계와 구현이 단순해지며, 별도의 중간 과정이 불필요.
- 유연성: 데이터의 변화에 더 잘 적응할 수 있으며, 새로운 데이터에 대한 일반화 능력이 향상됨.
SSD의 구조와 작동방식

SSD 모델은 VGG16을 base network로 사용하고 보조 network(auxiliary network)를 추가한 구조를 가지고 있다. 두 network를 연결하는 과정에서 fc layer를 conv layer로 대체하면서 detection 속도가 향상된다. SSD 모델은 Convolutional Network 중간의 conv layer에서 얻은 feature map을 포함시켜, 총 6개의 서로 다른 scale의 feature map을 예측에 사용한다. 또한 feature map의 각 cell마다 서로 다른 scale과 aspect ratio를 가진 bounding box인 default box를 사용하여 객체의 위치를 추정한다.
*default box: YOLO에서 사용하는 앵커박스(anchor box)와 같은 개념이라고 보면 됨
풀어서 쓰자면 다음과 같다.
1. 특징 추출 (Feature Extraction)
300 * 300의 이미지를 입력받아 CNN(Convolutional Neural Network)을 통해 특징 맵(feature map)을 추출. SSD에서는 VGG16과 같은 기본 네트워크(backbone)를 사용하여 다양한 스케일의 특징 맵을 생성한다.
YOLO v1 모델의 경우 7x7(x30) 크기의 feature map만을 사용했다. 하지만 이처럼 단일한 scale의 feature map을 사용할 경우, 다양한 크기의 객체를 포착하는 것이 어렵다는 단점이 있다. 이러한 문제를 해결하기 위해 저자는 SSD network 중간에 존재하는 conv layer의 feature map들을 추출하여 detection 시 사용하는 방법을 제안했다.
2. 멀티 스케일 특징 맵 (Multi-scale Feature Maps)
SSD는 기본 네트워크의 여러 계층(layer)에서 특징 맵을 추출한다. 각 계층은 다른 해상도를 가지며, 작은 물체는 낮은 계층에서, 큰 물체는 높은 계층에서 더 잘 감지된다. 이처럼 여러 해상도의 특징 맵을 사용하여 다양한 크기의 객체를 탐지할 수 있다.
3. 앵커 박스 (Anchor Boxes) 생성
각 특징 맵의 위치마다 여러 크기와 비율의 앵커 박스를 생성한다. 이 앵커 박스들은 객체가 있을 가능성이 있는 후보 영역을 나타낸다. 예를 들어, 하나의 위치에서 여러 개의 앵커 박스(정사각형, 직사각형 등)를 생성한다.
4. 분류 및 위치 조정 (Classification and Localization)
각 앵커 박스에 대해 두 가지 예측을 수행한다:
- 분류 (Classification): 각 앵커 박스에 대해 특정 클래스(예: 고양이, 강아지 등)일 확률을 예측
- 위치 조정 (Localization): 각 앵커 박스의 위치와 크기를 실제 객체에 맞게 조정하기 위해 오프셋을 예측
이 예측은 CNN을 통해 이루어지며, 모든 앵커 박스에 대해 동시에 수행된다.
5. 손실 함수 (Loss Function)
SSD는 분류 손실과 위치 손실을 결합한 멀티태스크 손실 함수(Multi-task Loss Function)를 사용하여 모델을 학습시킨다. 분류 손실은 크로스 엔트로피 손실(cross-entropy loss)을 사용하고, 위치 손실은 스무드 L1 손실(smooth L1 loss)을 사용한다.
6. 비최대 억제 (Non-Maximum Suppression, NMS)
최종적으로, 각 앵커 박스에서 예측된 바운딩 박스를 후처리한다. 이 과정에서 동일한 객체에 대한 여러 중복된 예측을 제거하고, 신뢰도가 높은 박스만 남긴다. 이를 비최대 억제(NMS)라고 한다.
Multi-scale feature maps for detection
기본 네트워크 다음에 여러 합성곱 피처 계층을 덧붙였다. 이 계층의 크기는 차례로 줄어드는데, 다양한 스케일로 객체를 탐지하기 위해서이다. 각 피처 계층마다 객체 탐지를 수행하는 것.
Convolutional predictors for detection
추가된 각 피처 계층은 합성곱 필터를 통해 객체 탐지를 수행하는데 이 때 탐지된 결과의 크기는 일정하다.
SSD 모델은 기본 네트워크 끝에 여러 피처 계층을 덧붙였다. 각 피처 계층마다 '다양한 스케일과 가로세로 비율을 갖는 디폴트 박스의 좌표값'과 '해당 디폴트 박스가 나타내는 객체의 존재 여부 신뢰도'를 예측한다. 이때 경계 박스 좌표는 디폴트 박스를 기준으로 상대 좌표로 예측하며, 300 x 300 크기의 입력 이미지를 받는 SSD는 448 x 448 크기의 입력 이미지를 받는 YOLO보다 더 빠르고 정확합니다(PASCAL VOC 2007 실험 결과)
SSD의 Training
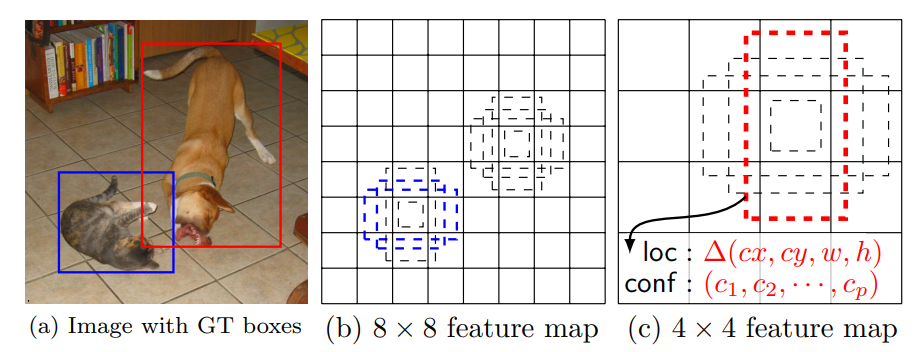
(a) SSD는 훈련 시, 입력 이미지와 각 객체별 참 경계 박스(ground truth boxes)만 필요로 한다. 입력 이미지에 합성곱 연산을 해 피처 맵을 구하고 이 때 앞서 말한 여러 차례 합성곱 연산을 해서 다양한 크기의 피처 맵을 만든다. 다양한 피처 맵마다 각 픽셀당 서로 다른 비율을 갖는 디폴트 박스가 있다.
(b)와 (c)에서 점선으로 표시된 것을 디폴트 박스라고 한다. 디폴트 박스는 한 픽셀당 네 가지가 있다. 그러므로 (b) 8 x 8 피처 맵에서는 디폴트 박스가 총 8 * 8 * 4개, (c) 4 x 4 피처 맵에서는 4 * 4 * 4개가 있는 것
각 디폴트 박스마다 '경계 박스 좌표'와 '그 경계 박스의 객체 신뢰도 점수'를 예측한다. 위 (c) 그림에서 보다시피 객체 신뢰도 점수를 c_1, c_2, ... , c_p로 표현한다. 훈련 단계에서 디폴트 박스를 먼저 참 경계 박스(ground truth boxes)와 매칭한다. 예를 들어, 두 가지 디폴트 박스가 고양이 한 마리, 강아지 한 마리와 매칭됐다고 한다면, 이 두 디폴트 박스를 positive로 간주하고, 나머지 디폴트 박스는 negative로 간주한다.
Default boxes and aspect ratios
SSD 네트워크에서는 다양한 피처 맵을 구한다고 했다. 다양한 피처 맵마다 디폴트 박스와 피처 맵의 각 픽셀과 연관시킨다. 각 픽셀마다 경계 박스 좌표와 객체 클래스 신뢰도 점수를 구한다. 객체 클래스 신뢰도 점수란 해당 디폴트 박스에 객체가 존재하는지 여부를 점수화해 나타낸 값을 뜻한다. 객체 클래스가 c개 있다고 하면, 각 디폴트 박스마다 예측하는 값은 (c + 4)개이다(경계 박스 좌표는 4개이기 때문에). 한 픽셀마다 갖는 디폴트 박스가 k개라 하면, 한 픽셀마다 예측하는 값은 (c + 4)k개이다. 만약 피처 맵 크기가 m x n이라면 피처 맵당 예측하는 값은 (c + 4)kmn개이다. 디폴트 박스는 Faster R-CNN에서 사용한 앵커 박스와 비슷하다. 하지만 SSD에서는 다양한 해상도를 갖는 피처 맵을 활용한다는 점이 다르다. 이렇게 피처 맵 크기를 다양하게 활용하고, 디폴트 박스의 비율도 여러 개 사용하기 때문에 효과적으로 객체를 탐지할 수 있다.
2-2. Training
Matching strategy
훈련하는 동안 어떤 디폴트 박스가 참 경계 박스와 매칭되는지 확인해야 한다. 참 경계 박스에 매칭되는 디폴트 박스를 찾는 방식으로 훈련이 진행된다. 매칭되는 디폴트 박스는 크기도, 위치도, 가로세로 비율도 다양하다. 참 경계 박스와 IoU가 0.5보다 큰 디폴트 박스를 찾는다. IoU가 가장 큰 디폴트 박스 하나만 찾는 게 아니라, 우선은 0.5보다 큰 모든 디폴트 박스를 찾는 것이다.
1. Ground-truth Box와 IoU를 비교하여 점수가 가장 높은 Default Bounding Box 찾기
2. Ground-truth Box와 IoU를 비교하여 점수가 0.5 보다 큰 Default Bounding Boxes 찾기
위의 이미지를 보면, 고양이는 2개의 파랑 Default Bounding Box들과 매칭되었고,
강아지는 1개의 Red Default Bounding Box와 매칭된 것을 볼 수 있다.
매칭된 Default Bounding Box는 Positive, 나머지는 Negative로 간주하게 되는데, 대부분의 Default Bounding Boxes들은 Negative로 간주된다. 하지만 이 경우, Negative 데이터가 많아져 불균형 문제가 발생하므로 이를 해결하기 위해 Hard Negative Mining이 사용된다. Negative와 Positive 비율이 3:1이 되도록 Negative를 Confidence Loss 순으로 내림 정렬하고, 선택하여 Hard Negative Mining을 사용했을 때 모델의 최적화가 더 빠르고 안정적이었다고 논문에서 이야기한다.
그리고 Data Augmentation을 사용하여 데이터를 증가 시키는 작업을 수행한다. Data Augmentaiton으로 생성한 다양한 데이터를 학습했을 때 다양한 크기의 객체가 더 잘 탐지 되는 효과가 있다고 이야기한다.
SSD는 가중치가 적용된 Localization Loss(Lloc)와 Confidence Loss(Lconf)의 합을 Loss Function으로 사용한다.

위 식에서 N은 매칭된 Default Bounding Boxes의 개수이며, 가중치 α는 1의 값을 갖는다.

Lloc는 Predicted Box(l)와 Ground-truth Box(g) 사이의 Smooth L1 Function이며, g 파라미터는 다음과 같이 계산된다.

Default Bounding Box(d)의 center는 (cx, cy)이고 너비와 높이는 각각 w와 h로 표현된다.

신뢰도 손실은 각 객체 클래스마다 소프트맥스 함수로 구한다.
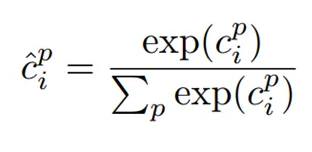
Default Bounding Box 크기
Choosing scales and aspect ratios for default boxes
다양한 객체 크기를 다루기 위해 Overfeat이나 SPP-net 모델에서는 이미지를 다양한 크기로 처리한다. 하지만, SSD에서는 각 합성곱 계층의 피처 맵을 활용해 같은 효과를 낸다. 이렇게 하면 모든 객체 스케일끼리 파라미터도 공유할 수 있다. 또한, 각 합성곱 계층의 피처 맵을 활용하기 때문에 객체의 전반적인 특성도 파악할 수 있고, 세세한 특성도 파악이 가능하다.
이런 방식으로, 여러 피처 맵을 활용해 객체 탐지를 수행하는데 이 때 사용하는 k개 디폴트 박스 크기는 피처 맵마다 일정하다. 그러면 큰 피처 맵에서는 디폴트 박스가 작은 객체를 탐지할 테고, 작은 피처 맵에서는 큰 객체를 탐지할 것이다.
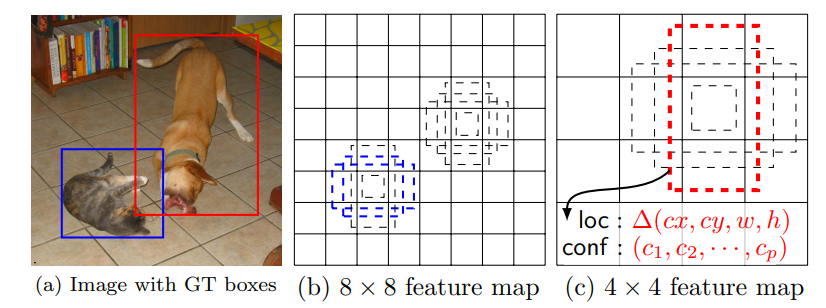
상대적으로 크기가 큰 강아지는 4 x 4 피처 맵에서 위아래로 길쭉한 디폴트 박스가 탐지하는 반면, 크기가 작은 고양이는 8 x 8 피처 맵에서 좌우로 길쭉한 디폴트 박스가 탐지한다.
Hard negative mining
디폴트 박스를 매칭하고 나면, 대부분 디폴트 박스는 negative일 것이다. 전체 디폴트 박스 개수는 상당히 많지만 참 경계 박스와 매칭된 디폴트 박스는 적기 때문이다. 그러면 positive 훈련 샘플과 negative 훈련 샘플 간 불균형이 심해지므로 모든 negative 훈련 샘플을 사용하는 대신, 신뢰도 손실 점수를 기반으로 negative 샘플을 제외하여 최종적으로 negative 샘플과 positive 샘플 비율이 3:1 정도가 되게 맞춘다. 더 빠르고 효과적으로 훈련을 하기 위해.
다양한 크기의 객체를 탐지하기 위해, 다양한 크기의 Feature Map을 사용한다고 언급했다. 그림 (b), (c)에서 볼 수 있듯이 강아지는 4 x 4 Feature Map에서는 Red Default Bounding Box에 의해 탐지 되었지만, 8 x 8 Feature Map에서는 Default Bounding Boxes의 크기가 강아지보다 모두 작아서 강아지가 탐지 되지 않는 것을 확인할 수 있다. 즉, 다양한 크기와 비율의 Feature Map과 Default Bounding Boxes들을 통해 다양한 크기의 객체를 탐지할 수 있게 되는 것이 바로 SSD의 핵심 포인트이다.
좀 더 자세한 Training방법....
1. 데이터 준비 (Data Preparation)
데이터셋: VOC, COCO와 같은 객체 탐지용 데이터셋을 사용합니다. 각 이미지에는 객체의 클래스와 위치를 나타내는 바운딩 박스 정보가 포함되어 있습니다.
데이터 전처리: 입력 이미지 크기를 고정된 크기(예: 300x300 또는 512x512)로 조정하고, 정규화 등의 전처리 과정을 수행합니다.
2. 앵커 박스 매칭 (Anchor Box Matching)
GT 박스와 앵커 박스 매칭: 각 이미지에 대해, Ground Truth (GT) 바운딩 박스를 여러 크기와 비율의 앵커 박스와 매칭시킵니다.
IoU 계산: 각 앵커 박스와 GT 박스 간의 IoU(Intersection over Union)를 계산합니다. IoU가 특정 임계값(예: 0.5) 이상인 앵커 박스를 양성 예로, 그 외의 앵커 박스를 음성 예로 간주합니다.
3. 모델 아키텍처 (Model Architecture)
기본 네트워크: VGG16 또는 ResNet과 같은 CNN을 사용하여 특징 맵을 추출합니다.
멀티스케일 특징 맵: 다양한 스케일의 특징 맵을 사용하여 작은 객체부터 큰 객체까지 탐지할 수 있도록 합니다.
예측 레이어: 각 특징 맵 위치에서 앵커 박스에 대한 클래스 확률과 위치 오프셋을 예측하는 컨볼루션 레이어를 추가합니다.
4. 손실 함수 (Loss Function)
멀티태스크 손실: 분류 손실과 위치 손실을 결합한 손실 함수를 사용합니다.
분류 손실 (Classification Loss): 크로스 엔트로피 손실(cross-entropy loss)을 사용하여 각 앵커 박스에 대한 클래스 확률 예측을 평가합니다.
위치 손실 (Localization Loss): 스무드 L1 손실(smooth L1 loss)을 사용하여 예측된 바운딩 박스 위치와 GT 박스 위치 간의 차이를 평가합니다.
5. 학습 과정 (Training Process)
배치 처리: 여러 이미지로 구성된 배치를 입력으로 사용하여 병렬 처리합니다.
역전파 (Backpropagation): 손실 함수를 최소화하기 위해 역전파 알고리즘을 사용하여 네트워크 가중치를 업데이트합니다.
옵티마이저 (Optimizer): 주로 Adam이나 SGD(Stochastic Gradient Descent)와 같은 옵티마이저를 사용하여 학습률을 조절하며 가중치를 업데이트합니다.
6. 데이터 증강 (Data Augmentation)
학습 데이터의 다양성을 높이기 위해 여러 가지 데이터 증강 기법을 사용합니다. 예를 들어, 랜덤 크롭, 회전, 색상 변형 등을 적용하여 모델이 다양한 상황에서도 일반화될 수 있도록 합니다.
7. 평가 (Evaluation)
검증 데이터셋: 학습 중간에 모델의 성능을 평가하기 위해 검증 데이터셋을 사용합니다.
mAP(mean Average Precision): 객체 탐지 성능을 평가하기 위해 주로 사용되는 지표로, 다양한 임계값에서의 평균 정확도를 계산합니다.
Experimental Results
SSD에서 사용한 기본 네트워크는 VGG-16이다. 구체적으로 말하면, ILSVRC CLS-LOC 데이터셋에서 사전 훈련된 VGG-16.
PASCAL VOC 2007
PASCAL VOC 2007 테스트 데이터셋에서 Fast R-CNN, Faster R-CNN과 비교해 SSD 성능을 실험했다. 세 모델 모두 기본 네트워크로 사전 훈련된 VGG-16을 사용하는데 이를 PASCAL VOC 2007에서 파인튜닝한 것이다.
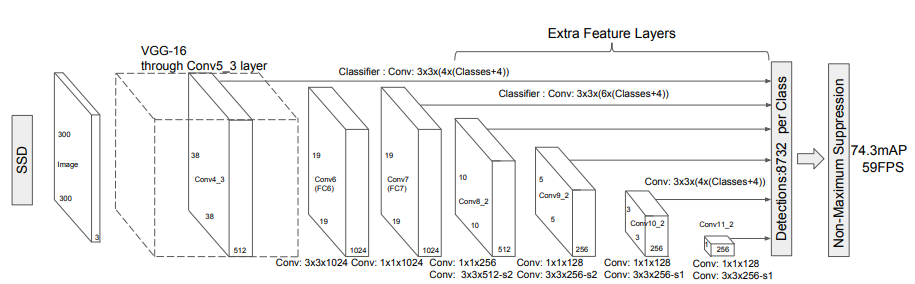
그림에서 보다시피 conv4,_3, conv7, con8_2, conv9_2, conv10_2, conv11_2를 활용해 경계 박스 좌표와 객체 클래스 신뢰도를 구한다. conv4_3, conv10_2, conv11_2에서는 4가지 디폴트 박스만 사용했다. 나머지 합성곱 계층에서는 6가지 디폴트 박스를 사용했다.
훈련 시 학습률 0.001로 40,000번 이터레이션을 수행한다. 이어서 학습률 0.0001과 0.00001에서 10,000번씩 이터레이션을 더 수행한다. 다음 SSD와 Fast R-CNN, Faster R-CNN과 성능을 비교한 표를 보면,

SSD300은 300 x 300 입력 이미지를 사용한 SSD 모델,
SSD512는 512 x 512 입력 이미지를 사용한 SSD 모델을 뜻한다.
SSD300(②)만으로도 Faster R-CNN(①)보다 성능이 좋다. (VOC 2007, 2012, MS COCO 데이터를 활용한)
SSD512는 mAP 81.6%로 성능이 더 좋다. 표에서 알 수 있듯이 데이터가 많을수록, 입력 이미지가 클수록 성능이 좋다는 것을 알 수 있다.
Inference time (추론시간)
SSD 구조상 디폴트 박스가 굉장히 많기 때문에, 추론(inference) 단계에서는 비최댓값 억제(NMS)를 적용한다. 먼저, 신뢰도 임계값을 0.01로 정해서 많은 경계 박스를 필터링 한 후, IoU 0.45를 기준으로 NMS를 적용한다. 이미지당 탐지 결과를 상위 200개만 남기는데, 이 단계는 SSD300에서 이미지마다 1.7ms가 걸린다. 배치 크기를 8로 설정하고, Intel Xeon E5-2667v3@3.20GHz에서 Titan X와 cuDNN v4로 실험한 결과이다.
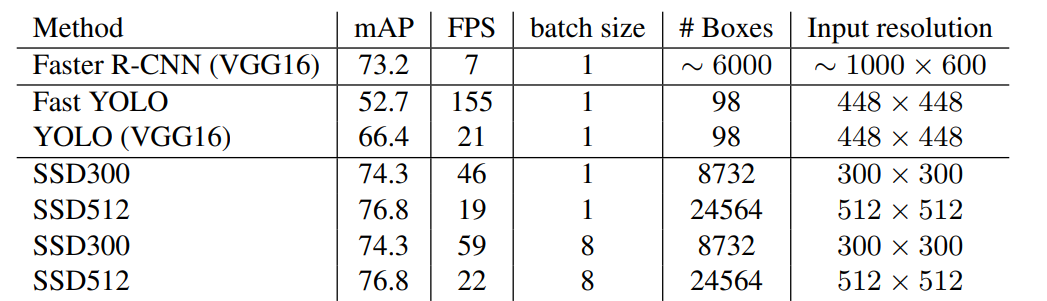
SSD300과 SSD512 모두가 Faster R-CNN보다 속도도 빠르고 mAP도 높다. Fast YOLO보다 속도는 느리지만 mAP가 훨씬 높다. SSD300이 mAP 70%를 넘으면서 실시간 객체 탐지가 가능한 속도를 보인 최초 모델이다. 기본 네트워크인 VGG-16에서 전체 순전파 시간의 80%를 차지한다. 따라서 더 빠른 기본 네트워크를 사용한다면 SSD512도 실시간 탐지가 가능한 수준이 될 것으로 예상된다.
SSD가 뛰어난 성능을 보이는 건 여러 특성들 때문이겠지만 그 중에서도 특히,
1. Single Stage Object Detection:
단일 네트워크를 통해 객체의 위치와 클래스를 동시에 예측함으로 별도의 영역제안단계(region proplsal stage)가 필요 없기 때문에 빠르고 효율적이라는 것과
2. Multi-scale Feature Maps:
여러 해상도의 특징 맵을 사용하여 다양한 크기의 객체를 탐지할 수 있으며
3. Multi-task Learning:
분류 손실과 위치 손실을 결합한 멀티태스크 손실 함수를 사용하기 때문에 객체의 클래스와 위치를 동시에 학습하여 효율성과 성능을 높이는 것이라고 볼 수 있을 것 같다.