1. 캐글(Kaggle) 캐글사이트 2. 데이콘(Dacon) 데이콘 3. AI허브 4. 타이타닉 데이터 import pandas as pddf = pd.read_csv('https://bit.ly/fc-ml-titanic')
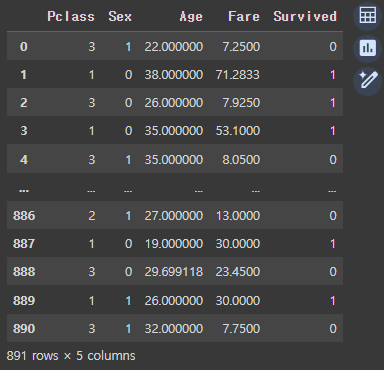
df
PassengerId: 승객 아이디
5. 데이터 전처리 5-1. 독립변수와 종속변수 나누기 # feature = ['Pclass', 'Sex', 'Age', 'Fare'] # 독립변수
# label = ['Survived'] # 종속변수
columns = ['Pclass', 'Sex', 'Age', 'Fare', 'Survived']
# 생존과 관련있는 컬럼 찾아보는 것이 목표df['Survived'].head()
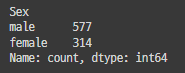
df['Survived'].value_counts()0: 사망 / 1: 생존
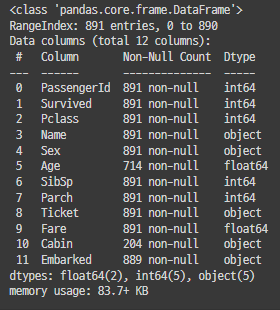
5-2. 결측치 처리 df.info()Age와 Cabin, Embarked에서 결측값 있음 확인
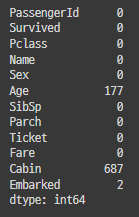
df.isnull().sum()
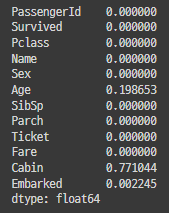
df.isnull().mean() # null의 비율
# Age는 생존과 밀접관련이 있을 수도 있으므로, null값은 평균값으로 대입하여 분석에 이용한다.
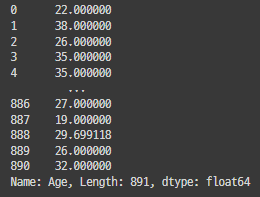
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Age']
5-3. 라벨 인코딩(Label Encoding)
df.info()Dtype : Object형은 될 수 있으면 숫자로 변환해 주는 것이 좋다.
# 성별을 수치화
df['Sex'].value_counts()
# 남자는 1, 여자는 0으로 변환하는 함수
def convert_sex(data):
if data == 'male':
return 1
elif data =='female':
return 0df['Sex'] = df['Sex'].apply(convert_sex)
df.head()int로 잘 변환되었다.
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()df['Embarked'].value_counts() # null은 제거
embarked = le.fit_transform(df['Embarked']) # 0: S, 1: C, 2: Q
embarked # null: 33 찾아보기 ㅎㅅㅎ
le.classes_ # 0: S, 1: C, 2: Q
5-4. 원 핫 인코딩(One Hot Encoding) df['Embarked_num'] = LabelEncoder().fit_transform(df['Embarked'])
df.head()pd.get_dummies(df['Embarked_num'])
df = pd.get_dummies(df, columns=['Embarked'])
df.head()
df = df[columns]
df
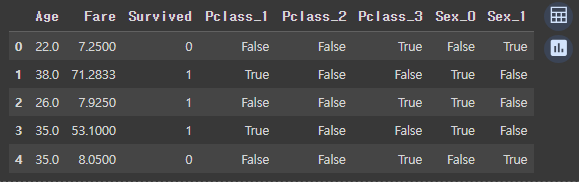
df = pd.get_dummies(df, columns=['Pclass', 'Sex'])
df.head()Pclass와 성별도 원 핫 인코딩처리
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(df.drop('Survived', axis=1), df['Survived'], test_size=0.2, random_state=2024)